Task 3: Visual Relation Detection
Visual relation detection (VRD) is a novel research problem that is beyond the recognition of single object entity. It requires the visual system to understand many perspectives of two entities, including appearance, action, intention, and interactions between them. Specifically, it aims to detect instances of visual relations of interest in a video, where a visual relation instance is represented by a relation triplet <subject,predicate,object> with the bounding-box trajectories of the subject and object during the relation happening (as shown in Figure 1).
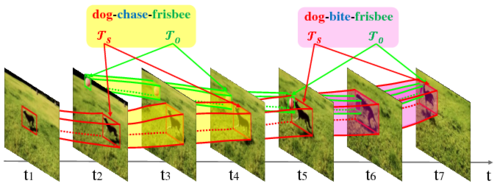
This challenge offers the first large scale video dataset for VRD and intends to pave the way for the research on relation understanding in videos. In the task, participants are encouraged to develop methods that can not only recognize a wide range of visual relations from 80 object categories and 50 predicate categories, but also spatio-temporally localize various visual relation instances in a user-generated video. Note that the detection of social relations (e.g. “is parent of”) and emotional relations (e.g. “like”) is outside the scope of this task.