Main Task: Video Relation Detection
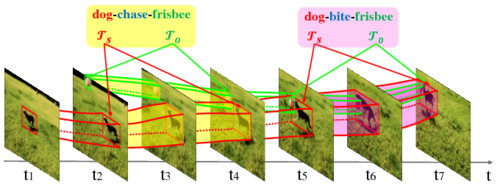
Video Visual Reltion Detection is a novel research problem that is beyond the recognition of single object entity. It requires the visual system to understand many perspectives of two entities, including appearance, action, intention, and interactions between them. Specifically, it aims to detect instances of visual relations of interest in a video, where a visual relation instance is represented by a relation triplet <subject,predicate,object> with the bounding-box trajectories of the subject and object during the relation happening (as shown in Figure 1). Note that the detection of social relations (e.g. “is parent of”) and emotional relations (e.g. “like”) is outside the scope of this task.
The top-1 solution in VRU'19 challenge, including precomputed features and bounding box trajectories, are released at link1 (link2) to facilitate participation. Please kindly cite this paper if you use it in your work.